Introduction to Big Data
Big Data was just another buzzword for me and I never had any real contact besides the typical requests of data scientists to move data to a specific endpoint of a Data Lake in the overall architecture.
This changed, when I got the opportunity to have a closer look at a big data project in a business context. I usually don’t like to deal with new tech stuff unprepared, so I filled in some blanks by reading articles, a few books (The Enterprise Big Data Lake [datalake], Practical Enterprise Data Lake Insights [practical], Big Data [bigdata] and Hadoop: The Definitive Guide [hadoop]) and just started playing with it.
This led to lots of insights and Aha!-moments and I really wanted to write about, but unfortunately not only the name is big. Condensing all the stuff I’d like to address is quite difficult, so this is the start of a small series about the groundwork and (at least to me) interesting tools and aspects.
What is Big Data? &
From my impression the biggest thing in the big data idea is the shift away from storing processed or in some ways refined data to just storing anything as is - just in case it might become useful later.
This initially sounds like a good idea, but storing everything piles up pretty quickly and gets even worse when you actually work with it:

Managing complexity &
There have been several iterations of tackling the overall complexity on the storage level and like all good stories it started with SQL.
Once upon a time, there were Data Warehouses with big databases, which kept everything in rigid schemas. Unfortunately this introduced complex requirements for scaling and made redundancy even worse, but did the job for a while and everyone was happy…
Later on they were augmented or replaced by Data Lakes and Data Marts, which did some things differently:
-
Data is split by domain of origin or simply use-case
-
No schema is enforced on write and everything stays as-is in mostly flat-file
-
The problem of handling the actual data is offloaded to Hadoop
What is Hadoop? &
Hadoop is an open-source Java framework that manages large quantities of data and provides means for further processing. We are going to cover the processing of the actual data with MapReduce in a follow-up article, but before we can do that we have to talk about the architecture and the major components first:
-
Hadoop Distributed File System (HDFS) - is the underlying distributed filesystem and allows the Hadoop nodes to operate on local data.
-
Yet Another Resource Negotiator (YARN) - is the resource-management part of the system and responsible for scheduling jobs and resource allocation.
-
MapReduce - is a programming model for the actual processing in a divide-and-conquer-way and is going to be covered in a further post.
-
Hadoop Common - is a collection of all supporting tools and libraries.
Architecture &
The core architecture of HDFS is based on a leader/follower principle with a strong focus on resiliency and redundancy.
| 1 | Namenodes keep track of every block and store metadata like the name or the count of active replicas and answer questions of clients which datanodes have a copy of the desired block. |
| 2 | Clients use this information to connect directly to the datanodes and load the actual data. |
| 3 | When a client wants to write data it again consults the namesnodes first and then writes the data to the datanodes. |
| 4 | And namenodes check if the data needs to be re-balanced or replicated based on different events like a datanode fault. |
How to use the API? &
Setting up Hadoop is a task on its own and heavily depends on which other tools should come along with it. During my tests I set up a Dockerfile for more complex examples further down the course of the articles, but there is a really handy in-memory suite available that covers our initial needs for now.
Startup and configuration is straight forward and requires just a few lines of code:
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://localhost:9000");
configuration.set("dfs.replication", "1"); (1)
String baseDir = Files.createTempDirectory("test_hdfs").toFile().getAbsoluteFile(); (2)
configuration.set(MiniDFSCluster.HDFS_MINIDFS_BASEDIR, baseDir.getAbsolutePath());
MiniDFSCluster.Builder builder = new MiniDFSCluster.Builder(configuration);
MiniDFSCluster cluster = builder.build(); (3)| 1 | Limit the replication to one, to avoid replication errors with only a single datanode. |
| 2 | Use a temp base directory on the host machine. |
| 3 | Build and run it. |
Write data &
Writing data just requires the typical combination of out-stream and writer and behaves like every other IO in Java:
FileSystem fileSystem = FileSystem.get(configuration); (1)
Path hdfsPath = new Path(HADOOP_FILE);
FSDataOutputStream fsOut = fileSystem.create(hdfsPath);
OutputStreamWriter outStreamWriter = new OutputStreamWriter(fsOut, StandardCharsets.UTF_8);
BufferedWriter bufferedWriter = new BufferedWriter(outStreamWriter);
bufferedWriter.write("data");
bufferedWriter.newline();
bufferedWriter.close();
outStreamWriter.close();
fsOut.close();
fileSystem.close()| 1 | We re-use the configuration from the setup example here as well. |
Read data &
And lastly reading data pretty much offers no surprises at all:
FileSystem fileSystem = FileSystem.get(configuration);
Path hdfsPath = new Path(HADOOP_FILE);
FSDataInputStream inputStream = fileSystem.open(hdfsPath);
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8));
String line = null;
while (null != (line = bufferedReader.readLine())) {
LOGGER.debug("Read line: %s", line);
}
inputStream.close();
fileSystem.close();In action &
Hadoop comes with different web interfaces, basically one for every moving part like the namenodes or the datanodes. From there we can access a file browser, which allows to actually see the content of our running instance.
In the default configuration the mini-cluster is started on a random port, which probably can be configured somehow, but printing it on startup is a way easier solution:
LOGGER.info(String.format("\n---\nCluster is ready\n URL = %s\nPath = %s\n---\n",
cluster.getHttpUri(0), cluster.getDataDirectory()));
---
Cluster is ready
URL = http://localhost:62280
Path = /var/folders/fb/k_q6yq7s0qvf0q_z971rdsjh0000gq/T/test_hdfs10722280644286762801/data
---That figured out we can see the file listing inside of our browser:
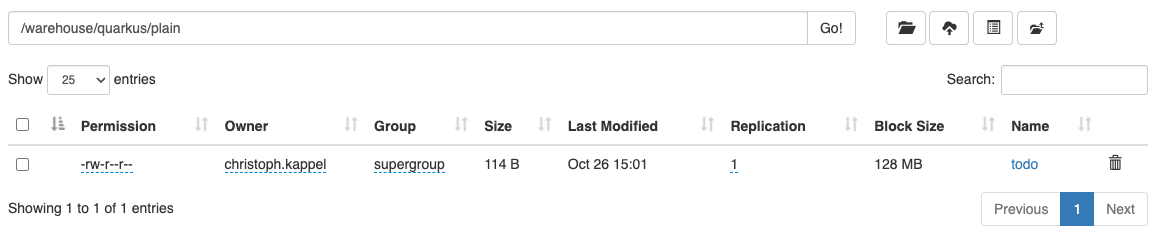
The interesting parts here are the replication and the block size. We’ve configured the actual replication level, so there is no surprise here, but the internal block size is quite a catch. Hadoop uses a default block size of 128 MB for every file and is geared towards bigger and fewer files in total.
This is especially relevant for namenodes, because they have to keep the blocks in active memory and this makes a failover to a secondary namenodes more difficult, but this is something for another day.
The web interfaces also happily provides more information about the used block and also serves the head or the tail of the file. The example in the showcase stores JSON data in a file and this can be seen in the file contents:
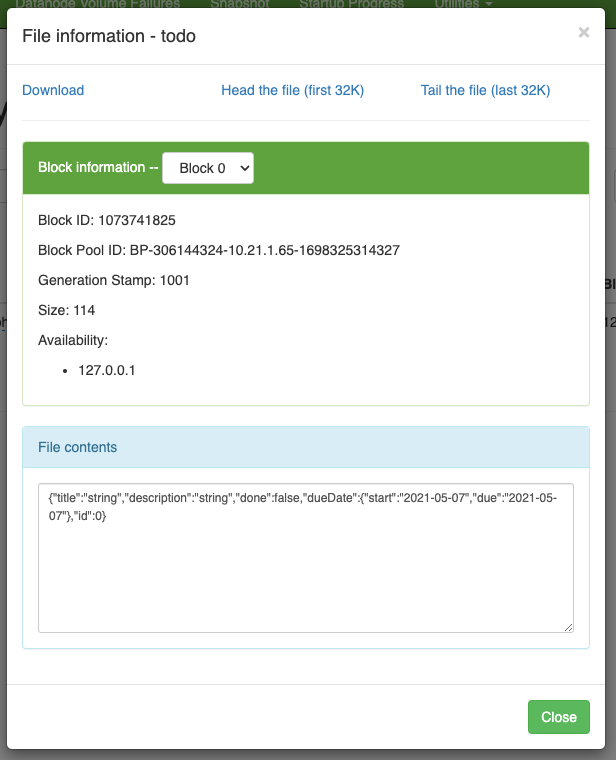
Since we know the block pool ID and the temp path of our cluster we can have a glance how this is stored under the hood:
BP-306144324-10.21.1.65-1698325314327 $ ls -R
current/ tmp/ scanner.cursor
./current:
finalized/ rbw/ VERSION
./current/finalized:
subdir0/
./current/finalized/subdir0:
subdir0/
./current/finalized/subdir0/subdir0:
blk_1073741825 blk_1073741825_1002.meta (1)
./current/rbw:
./tmp:
$ cat blk_1073741825
{"title":"string","description":"string","done":false,"dueDate":{"start":"2021-05-07","due":"2021-05-07"},"id":0} (2)
$ xxd blk_1073741825_1002.meta
00000000: 0001 0200 0002 0011 5d21 d1 ........]!. (3)| 1 | The interesting files here are some level down the directory hierarchy of our warehouse. |
| 2 | Hadoop and friends support four major formats: Plain text files, binary sequence files, Avro data files and Parquet |
| 3 | Next to the data file is a meta file, which contains a file header with version and a series of checksums for the sections of the block. |
Conclusion &
Hadoop offers a great variety of use-cases for companies starting from research to storing production data and satisfies the analytical needs of modern applications.
There are many benefits, but just to name a few:
-
Scalability - the architecture and computing model allow to quickly add new nodes, so the capacity can be increased easily.
-
Low cost - the software itself is FOSS, is supported by a rich set of tools and runs on COTS-hardware.
-
Flexibility - there is no preprocessing of data required, so if a new use-case is discovered existing data can also be utilized.
-
Resilience - data is replicated across multiple nodes and jobs can be re-scheduled on faults.
All examples can be found here:
Bibliography &
-
[datalake] Alex Gorelik, The Enterprise Big Data Lake: Delivering the Promise of Big Data and Data Science, O’Reilly 2019
-
[practical] Saurabh Gupta, Practical Enterprise Data Lake Insights: Handle Data-Driven Challenges in an Enterprise Big Data Lake, Apress 2018
-
[hadoop] Tom White, Hadoop: The Definitive Guide, O’Reilly 2009