OpenAPI and AsciiDoc in the Mix
I am getting more and more obsessed with centralized documentation and this isn’t because I enjoy writing documentation (which I unfortunately really do), but more due sheer lack of it in my day job and all the related issues we are currently facing.
Pushing ideas like the one from my previous post (Bringing documentation together) certainly helps to make writing docs easier, but there are still some loose ends to follow - like API.
So this post is going to demonstrate how OpenAPI (or formerly Swagger) can be converted into shiny AsciiDoc and be brought into the mix.
Why OpenAPI? &
There are many ways to document API (mind you any documentation is better than none!), but keeping established standards like OpenAPI and AsyncAPI (which isn’t to far off) really help to keep the cognitive churn low while trying to understand what a document is trying to convey.
And from a developer’s perspective there are many low-hanging fruits:
-
Code-first or API-first - you decide
-
Many generators in both directions available - like ktor-openapi-tools used in the example
-
Tools like Swagger UI and Redoc
-
Comes pre-assembled with a testing tool
Converting to AsciiDoc &
Again, there are dozens of options to select from.. Since I rely on the confluence publisher plugin my initial pick was something with Maven-integration as well, but unfortunately swagger2asciidoc has been unmaintained for quite some time. I actually tried to use it, but this was more like an educative endeavor for learning what happens to neglected packages.
The next best option and probably should have been my first pick anyway is OpenAPI with its exhaustive list of generators. They offer a plethora of different ways to convert specs and thankfully AsciiDoc is among them.
If we omit all nitty-gritty details it boils down to this call:
$ openapi-generator-cli generate -g asciidoc \
--skip-validate-spec \ (1)
--input-spec=src/site/asciidoc/spec/openapi.json \
--output=src/site/asciidoc (2)| 1 | Let us ignore version handling and maturity of my own spec for now |
| 2 | This is my preferred structure for Maven-based documentations |
| This can also be run from a container, see either openapi-generator-cli or have a look at my containerfile for even more dependencies. |
When everything works well a resulting document like this can be viewed:
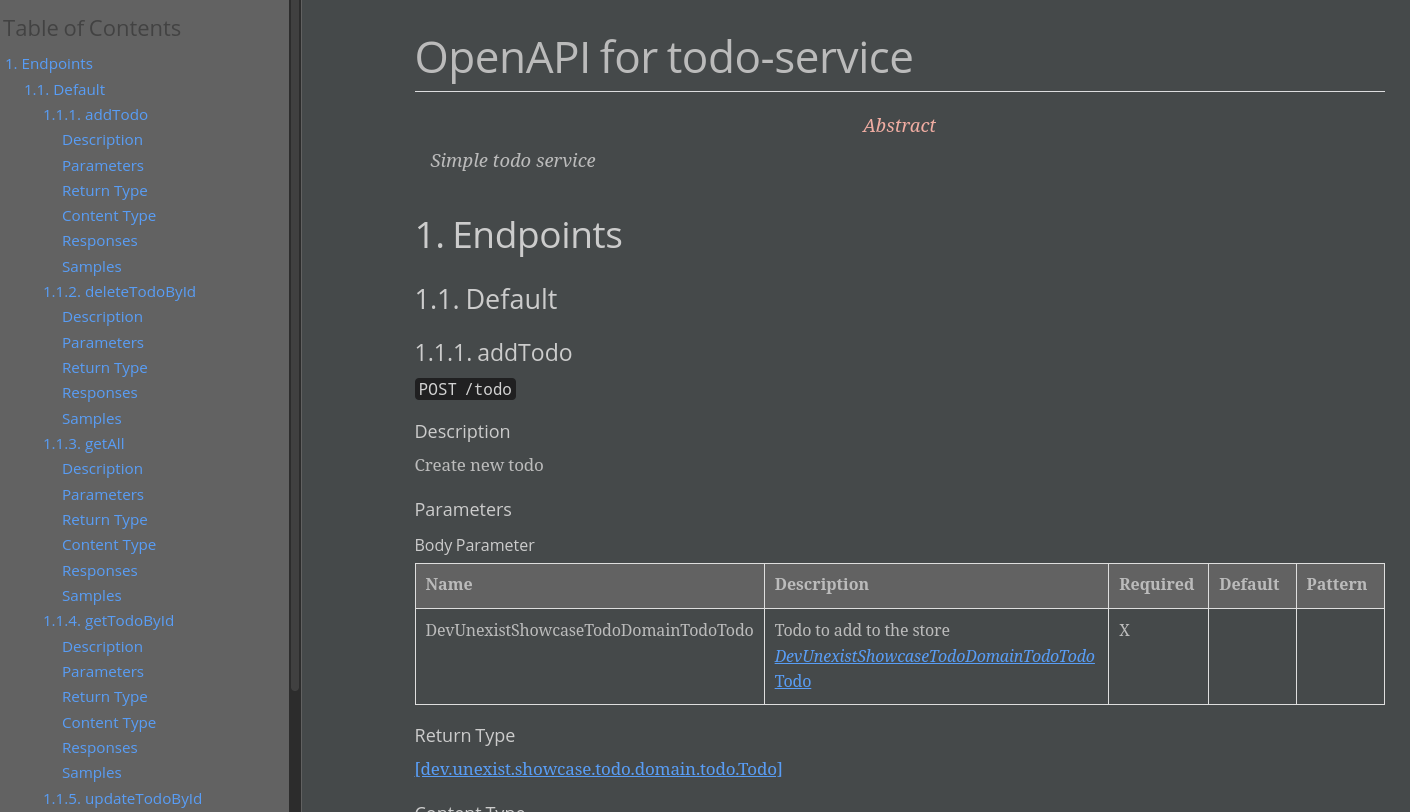
Customizing the document &
One of the strong points of AsciiDoc is surely its extensibility and this also true for the generator pipeline we are using now.
Per default, the generator offers a lot of different entrypoints to provide custom content for inclusion in the final document, without doing fancy hacks like e.g. an include of the generated document in your own one.
If you have a closer look at the actual generated document you can see lots of commented out includes like:
[abstract]
.Abstract
Simple todo service
// markup not found, no include::{specDir}intro.adoc[opts=optional]An introduction sounds like a good idea, so we could use the space there to inform our readers about the automatic updates of the document:
$ cat asciidoc/src/site/asciidoc/spec/intro.adoc
[CAUTION]
This page is updated automatically, please do *not* edit manually.After that we have to tell the generator to actually include our document.
When started, it is looking for these
templates.{fn-templates}.[1]
inside the specDir, something we haven’t set before, but we are quite able to do.
This only requires a minor change of our previous commandline:
$ openapi-generator-cli generate -g asciidoc \
--skip-validate-spec \ (1)
--input-spec=src/site/asciidoc/spec/openapi.json \
--output=src/site/asciidoc \
--additional-properties=specDir=spec/,useIntroduction=true (2)| 1 | Additional properties can be used to pass down configuration directly to the AsciiDoc renderer |
And hopefully, a run of the above rewards with an output like this:
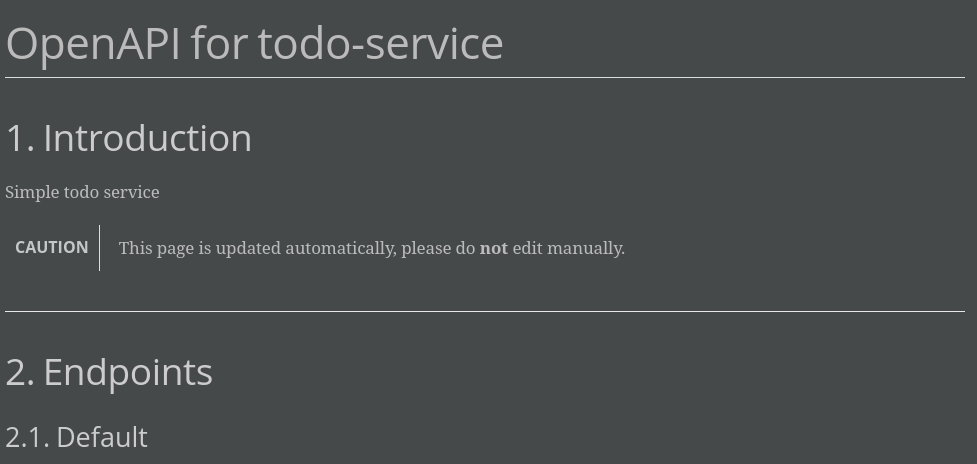
There are many more templates that can be filled and I would gladly supply a list, but at the time of writing I just can offer to grep the document on your own:
$ \grep -m 5 "// markup not found" src/site/asciidoc/index.adoc
// markup not found, no include::{specDir}todo/POST/spec.adoc[opts=optional]
// markup not found, no include::{snippetDir}todo/POST/http-request.adoc[opts=optional] (1)
// markup not found, no include::{snippetDir}todo/POST/http-response.adoc[opts=optional]
// markup not found, no include::{specDir}todo/POST/implementation.adoc[opts=optional]
// markup not found, no include::{specDir}todo/\{id\}/DELETE/spec.adoc[opts=optional]| 1 | Looks like we can also supply snippets to the example sections - neat! |
|
During my tests I stumbled upon a weird behavior, whereas there are different checks per index and generation phase, which have different requirements to the actual path. This made it necessary for me to fix this with a symlink in my builds:
|
Publish the document &
I think this is the third time I tease how everything can be pushed to Confluence, but since I don’t run any personal instance just feel teased again:
$ mvn -f pom.xml \
-DCONFLUENCE_URL="unexist.blog" \
-DCONFLUENCE_SPACE_KEY="UXT" \
-DCONFLUENCE_ANCESTOR_ID="123" \
-DCONFLUENCE_USER="unexist" \
-DCONFLUENCE_TOKEN="secret123" \
-P generate-docs-and-publish generate-resourcesConclusion &
What have we done here? Strictly speaking this doesn’t bring many advantages, especially when the tooling for OpenAPI looks so polished like this:
The ultimate goal of this is to create a central place where these specifications can be stored, without too many hurdles for non-dev stakeholders. Developers do well, when told the specs can be generated via Makefile.[2], but what about other roles like e.g. testers?
Back then we rolled a special infrastructure container, which basically included SwaggerUI along with the current versions of our specs, but infrastructure is additional work that has to be done and everything that leads to it must be maintained.
Whatever you do, proving easy access to documentation really helps to reach a common understanding and also might help to keep it up-to-date.
All examples can be found here: