Workflow engines on Quarkus
Discussions about flexibility as a requirement, usually lead to workflow engines, and although they are a more technical solution, than a real requirement, it is time to re-evaluate the current state of the support for Quarkus.
When you fire up Google and ask it for workflow engine quarkus, there is usually Camunda and
Kogito in the top10 of the results, so let us test both of them.
Camunda &
One of the better known engines, Camunda provides a rich feature set, a pretty mature codebase (0.7.15, >7 years) and surely cannot be a bad start.
Installation &
Although I’ve never seen Camunda outside of a SpringBoot context, their page states that there is an embeddable engine, which can be used inside of JAX-RS implementations. So this should and actually does partly work within Quarkus.
The essential dependencies are following with versions from the current BOM of Camunda:
<dependency>
<groupId>org.camunda.bpm</groupId>
<artifactId>camunda-engine</artifactId>
</dependency>
<dependency>
<groupId>org.camunda.bpm</groupId>
<artifactId>camunda-engine-rest</artifactId>
<classifier>classes</classifier>
</dependency>Modelling &
There aren’t many examples available, so it took me quite a while to get the engine running. After that and when I refreshed my knowledge how to actually create a BPMN diagram, I got a small and totally exciting example working:

On the pro sides, the Camunda Modeler is quite usable now (but still looks like a Java applet). I had different memories and ultimately generated the diagram by code, to avoid some of the problems with it, back then.
Problems &
There are a few noteworthy gotchas here:
How to use a datasource? &
Quarkus does not support JNDI, so the datasource must be passed to engine manually and the engine only way to access it is via CDI.
An easy way here just to include agroal and inject the default datasource:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jdbc-h2</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-agroal</artifactId>
</dependency>@Inject
AgroalDataSource defaultDataSource;| Setting the JDBC URL always prevented H2 from starting for me, so you also might want to check or rather avoid that. |
How to use CDI? &
Camunda also supports model integration for CDI, so the only thing that has to be done is adding engine-cdi as a dependency. Unfortunately, it relies on CDI features which are not supported (will probably be supported) by the CDI (ArC) implementation of Quarkus.
If you are interested in more backstory and a way to bypass this, please have a look here:
JSON handling is quite troublesome.. &
According to all the stuff I’ve read about, you just want to use the spin extension wherever possible. This doesn’t solve all problems, especially if you want to handle time and date, but every Java developer should be well aware of it.
What is the REST path to the engine? &
And just a minor issue, which actually took me quite a whole to understand: The path to the engine has been changed recently in Camunda:
Old: http://localhost:8080/rest/engine/default/process-definition/key/todo/start
New: http://localhost:8080/engine-rest/engine/default/process-definition/key/todo/startKogito &
Time to move on and check Kogito:
Kogito is designed from ground up to run at scale on cloud infrastructure. If you think about business automation think about the cloud as this is where your business logic lives these days. By taking advantage of the latest technologies (Quarkus, knative, etc.), you get amazingly fast boot times and instant scaling on orchestration platforms like Kubernetes.
Looking at this quote, they apparently are not afraid of bold statements. Although this project is in comparison to Camunda quite young (1.8.0, >2 years), it surely comes with a impressive feature set.
Kogito provides an extension for Quarkus, so the installation is pretty straight forward: All it really takes is to add one dependency:
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-quarkus</artifactId>
</dependency>Starting with Quarkus 2.1.0.CR1 it looks like the extension is part of the official group
and according to this example this should work, if you use a current snapshot.
It never did for me, but I will still mention it here for completeness:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-kogito</artifactId>
</dependency>Modelling &
With the help of their web-based and colorful online modeler, it was quite easy to get an initial workflow. Apparently, playing with it is quite funny and even CDI works out-of-the-box, so after a while I ended with up this:
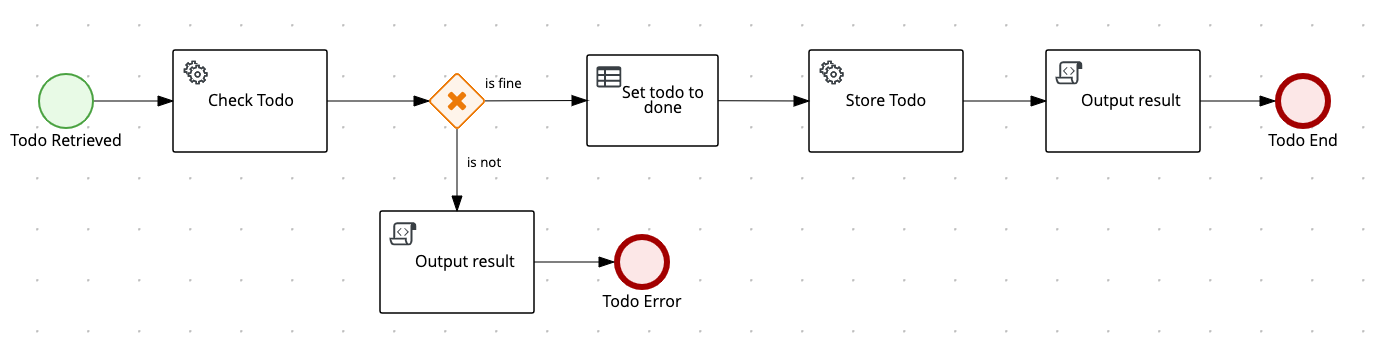
Rules engine &
One of the things I really liked is the easy integration of the rules engine Drools, which allows to write business rules in a DSL-like language:
package dev.unexist.showcase.todo.adapter;
dialect "mvel"
import dev.unexist.showcase.todo.domain.todo.TodoBase;
rule "isDone" ruleflow-group "TodoUpdater"
when
$todo: TodoBase(done != true)
then
modify($todo) {
setDone(true)Other really interesting features are to directly interface with Kafka and an available operator for Kubernetes. I really have to look into this operator, but let us talk about accessing messaging via Kafka:
Messaging &
I did know that there are devservices available since v1.13 and I also did a few tests with
a database in another showcase, but to my surprise the current version also uses a devservice
for Kafka.
Surprisingly, it not Kafka directly, but a re-implementation and API compatible project with
the lovely name Redpanda.
It comes with its own complete set of tools, which can be used to e.g. access topics:
$ brew install vectorizedio/tap/redpanda
$ rpk topic --brokers localhost:55019 list
$ rpk topic --brokers localhost:55019 create topic_in --replicas 1After a bit of testing, I must admit Redpanda is blazingly fast, I am really impressed.
Another thing that has to be included manually is the addon for CloudEvents, somehow it is not pulled automatically:
<dependency>
<groupId>org.kie.kogito</groupId>
<artifactId>kogito-addons-quarkus-cloudevents</artifactId>
</dependency>More modelling &
That out of the way, we can finally start modelling a new workflow with a message consumer and producer:

Problems &
Fire rule limit - what? &
If you ever see this inside of your log, it just means there is a rule that is called repetitively until a stack limit is reached. In my case it was just a test rule with a condition which could never be fulfilled.
Fire rule limit reached 10000, limit can be set via system property org.jbpm.rule.task.firelimit or
via data input of business task named FireRuleLimitHow to configure the topics? &
Since we are using a devservice the configuration part like the broker URL is done for us automatically. Still, I kind of missed a really essential part of the documentation:
# Messaging
mp.messaging.incoming.kogito_incoming_stream.connector=smallrye-kafka
mp.messaging.incoming.kogito_incoming_stream.topic=todo_in
mp.messaging.incoming.kogito_incoming_stream.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.outgoing.kogito_outgoing_stream.connector=smallrye-kafka
mp.messaging.outgoing.kogito_outgoing_stream.topic=todo_out
mp.messaging.outgoing.kogito_outgoing_stream.serializer=org.apache.kafka.common.serialization.StringSerializerDue to the internal wiring of Kogito, the incoming (kogito_incoming_stream) and the outgoing
(kogito_outgoing_stream) channels have specific and fixed names and any other name just
doesn’t work.
Another thing, that is easy to miss: The message name inside of the properties of the
start message or end message must to be the name of topic the message should be read from or
respectively send to:
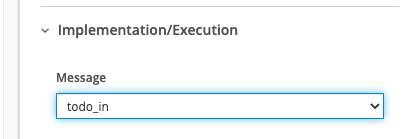
Benchmark &
I also did some benchmarks with wrk, to get some numbers on it, which probably speak for themselves:
wrk.method = "POST"
wrk.body = '{ "todo": { "description": "string", "done": false, "dueDate": { "due": "2022-05-08", "start": "2022-05-07" }, "title": "string" }}'
wrk.headers["Content-Type"] = "application/json"$ wrk -t1 -c1 -d30s -s payload.lua http://127.0.0.1:8080/camunda
Running 30s test @ http://127.0.0.1:8080/camunda
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.88ms 1.28ms 26.86ms 96.25%
Req/Sec 570.89 93.65 710.00 69.00%
17077 requests in 30.06s, 1.47MB read
Requests/sec: 568.17
Transfer/sec: 50.15KB$ wrk -t1 -c1 -d30s -s payload.lua http://127.0.0.1:8080/kogito
Running 30s test @ http://127.0.0.1:8080/kogito
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 60.27ms 269.05ms 1.97s 95.13%
Req/Sec 1.07k 278.63 1.49k 70.82%
30079 requests in 30.07s, 6.40MB read
Requests/sec: 1000.16
Transfer/sec: 217.81KB